Práctica 6: Despliegue de una aplicación "clusterizada" con Node Express
Introducción
Cuando se construye una aplicación de producción, normalmente se busca la forma de optimizar su rendimiento llegando a una solución de compromiso. En esta práctica echaremos un vistazo a un enfoque que puede ofrecer una victoria rápida cuando se trata de mejorar la manera en que las aplicaciones Node.js manejan la carga de trabajo.
Una instancia de Node.js se ejecuta en un solo hilo, lo que significa que en un sistema multinúcleo (como la mayoría de los ordenadores de hoy en día), no todos los núcleos serán utilizados por la aplicación. Para aprovechar los otros núcleos disponibles, podemos lanzar un cluster de procesos Node.js y distribuir la carga entre ellos.
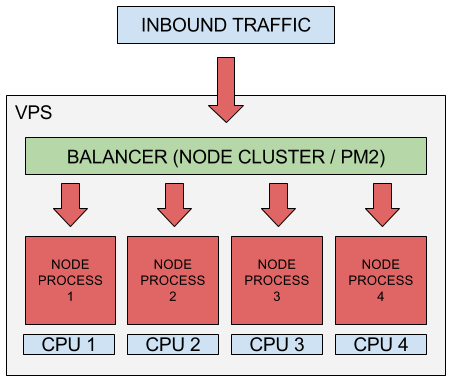
Tener varios hilos para manejar las peticiones mejora el rendimiento (peticiones/segundo) del servidor, ya que varios clientes pueden ser atendidos simultáneamente. Veremos cómo crear procesos hijos con el módulo de cluster de Node.js para, más tarde, ver cómo gestionar el cluster con el gestor de procesos PM2.
Un vistazo rápido a los clusters
El módulo de clúster de Node.js permite la creación de procesos secundarios (workers) que se ejecutan simultáneamente y comparten el mismo puerto de servidor. Cada hijo generado tiene su propio ciclo de eventos y memoria. Los procesos secundarios utilizan IPC (comunicación entre procesos) para comunicarse con el proceso principal de Node.js.
Tener múltiples procesos para manejar las solicitudes entrantes significa que se pueden procesar varias solicitudes simultáneamente y si hay una operación de bloqueo/ejecución prolongada en un worker, los otros workers pueden continuar administrando otras solicitudes entrantes; la aplicación no se detendrá hasta que finalice la operación de bloqueo.
La ejecución de varios workers también permite actualizar la aplicación en producción con poco o ningún tiempo de inactividad. Se pueden realizar cambios en la aplicación y reiniciar los workers uno por uno, esperando que un proceso secundario se genere por completo antes de reiniciar otro. De esta manera, siempre habrá workers ejecutándose mientras se produce la actualización.
Las conexiones entrantes se distribuyen entre los procesos secundarios de dos maneras:
-
El proceso maestro escucha las conexiones en un puerto y las distribuye entre los workers de forma rotatoria. Este es el enfoque por defecto en todas las plataformas, excepto Windows.
-
El proceso maestro crea un socket de escucha y lo envía a los workers interesados que luego podrán aceptar conexiones entrantes directamente.
Usando los clusters
Como hemos visto necesitamos que nuestro equipo tenga varias CPU para hacer que cada proceso corra en una CPU distinta. Por tanto, crearemos un servidor DEBIAN en AWS, pero en este caso no aceptaremos los valores por defecto, sino que crearemos una instancia con 2 vCPU's.
- Crea una nueva EC2 Debian y llámale "DebianNodejsCluster"
- El tipo de instancia seleccióna t2.medium. Fíjate que tiene 2 vCPU
- Recuerda crear un grupo de seguridad adecuado como en la práctica anterior. Dale el mismo nombre que a la EC2. También puedes usar el de la práctica anterior.
- Instala Node.js y Express como hicimos en la práctica anterior
Primero sin clúster
Para ver las ventajas que ofrece la agrupación en clústeres, comenzaremos con una aplicación de prueba en Node.js que no usa clústeres y la compararemos con una que sí los usa, se trata de la siguiente:
const express = require("express");
const app = express();
const port = 3000;
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.get("/api/:n", function (req, res) {
let n = parseInt(req.params.n);
let count = 0;
if (n > 5000000000) n = 5000000000;
for (let i = 0; i <= n; i++) {
count += i;
}
res.send(`Final count is ${count}`);
});
app.listen(port, () => {
console.log(`App listening on port ${port}`);
});
Esta aplicación contiene dos rutas, una ruta raíz / que devuelve la cadena Hello World! y otra ruta /api/n donde se toma n como parámetro y va realizando una operación de suma (el bucle for) cuyo resultado acumula en la variable count que se muestra al final.
Si a este parámetro n, le damos un valor muy alto, nos permitirá simular operaciones intensivas y de ejecución prolongada en el servidor. Le damos como valor límite 5000000000 para evitar una operación demasiado costosa para nuestro ordenador.
Task
- Debéis conectaros al servidor Debian mediante SSH
- Debéis crear un directorio para el proyecto de esta aplicación. Llámale
pruebacluster. - DENTRO del directorio ejecutaréis 2 comandos:
npm initpara crear automáticamente la estructura de carpetas y el archivopackage.json(Con ir dándole a <ENTER> a todas las preguntas, os basta)npm install expresspara instalar express para este proyecto
- Crea el archivo del programa, que podemos llamar
pruebacluster.js. Pega dentro el contenido de la aplicación que vimos anteriormente. - Tras esto, DENTRO del directorio, ya podéis iniciar la aplicación con:
node pruebacluster.js
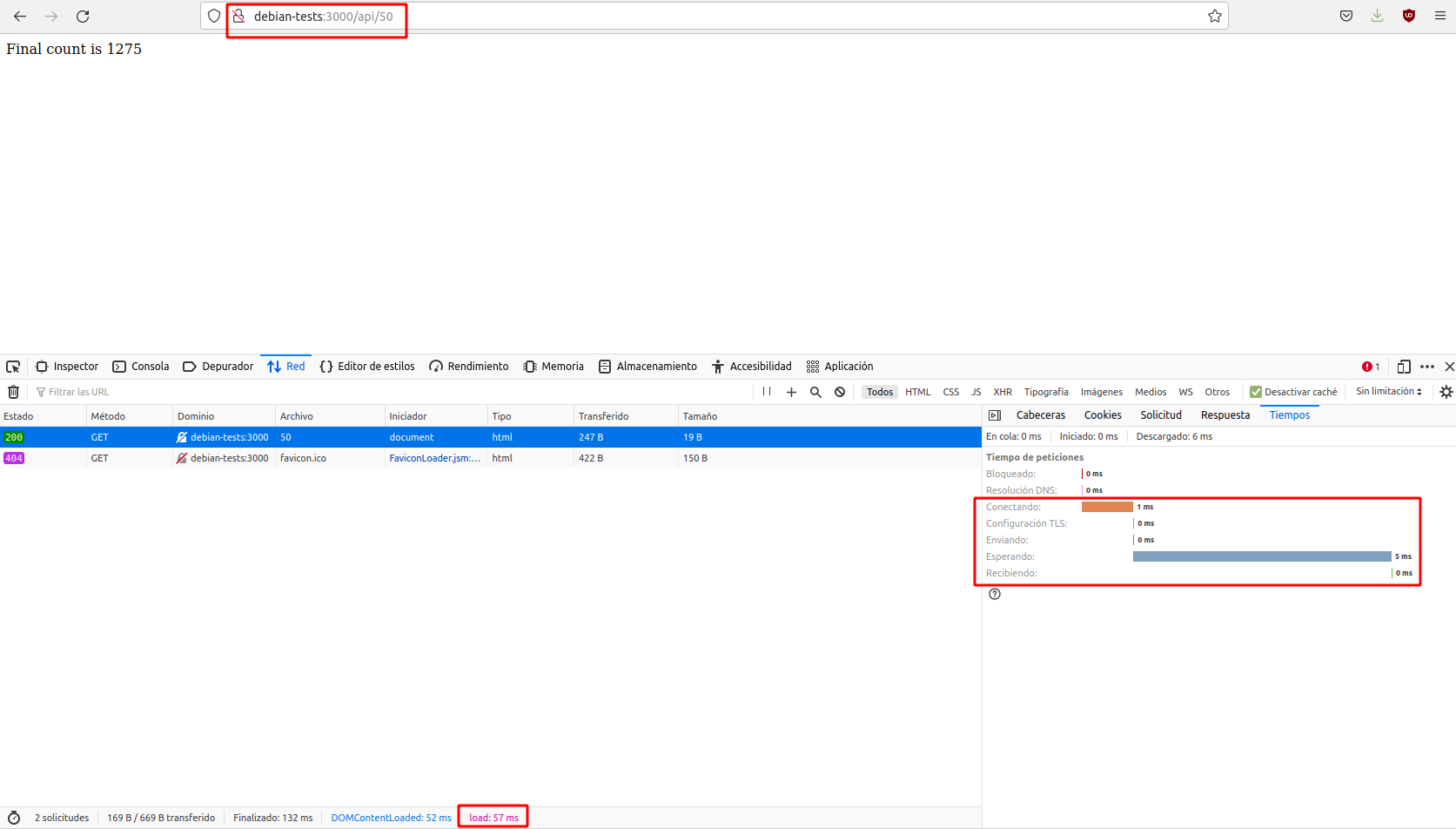
Para comprobarlo, podéis acceder a http://IP-maq-virtual:3000 o a http://IP-maq-virtual:3000/api/50 donde IP-maq-virtual es la IP de vuestro servidor Debian en AWS.
Vamos ver el tiempo que tardan en procesarse los programas en función del n. Usaremos Mozilla Firefox, aunque otros navegadores tienen herramientas similares. Antes de lanzar la aplicación abre las devoloper tools en Firefox. Ve al "menú hamburguesa" (las tres rayitas horizontales arriba a la derecha) - Más herramientas - Herramientas para desarrolladores. En la parte inferior del navegador se abrirán las herramientas y selecciona "Red". Ya podemos lanzar la aplicación.
Utilizada un valor de n relativamente pequeño, como el 50 del ejemplo anterior y comprobaréis que se ejecutará rápidamente, devolviendo una respuesta casi inmediata, del orden de milisegundos. Recuerda o anota el valor.
Hagamos otra simple comprobación para valores de n más grandes. Desplegada e iniciada la aplicación, acceded a la ruta http://IP-maq-virtual:3000/api/5000000000. Comprobad que ahora tarda varios segundos. Recuerda o anota el valor.
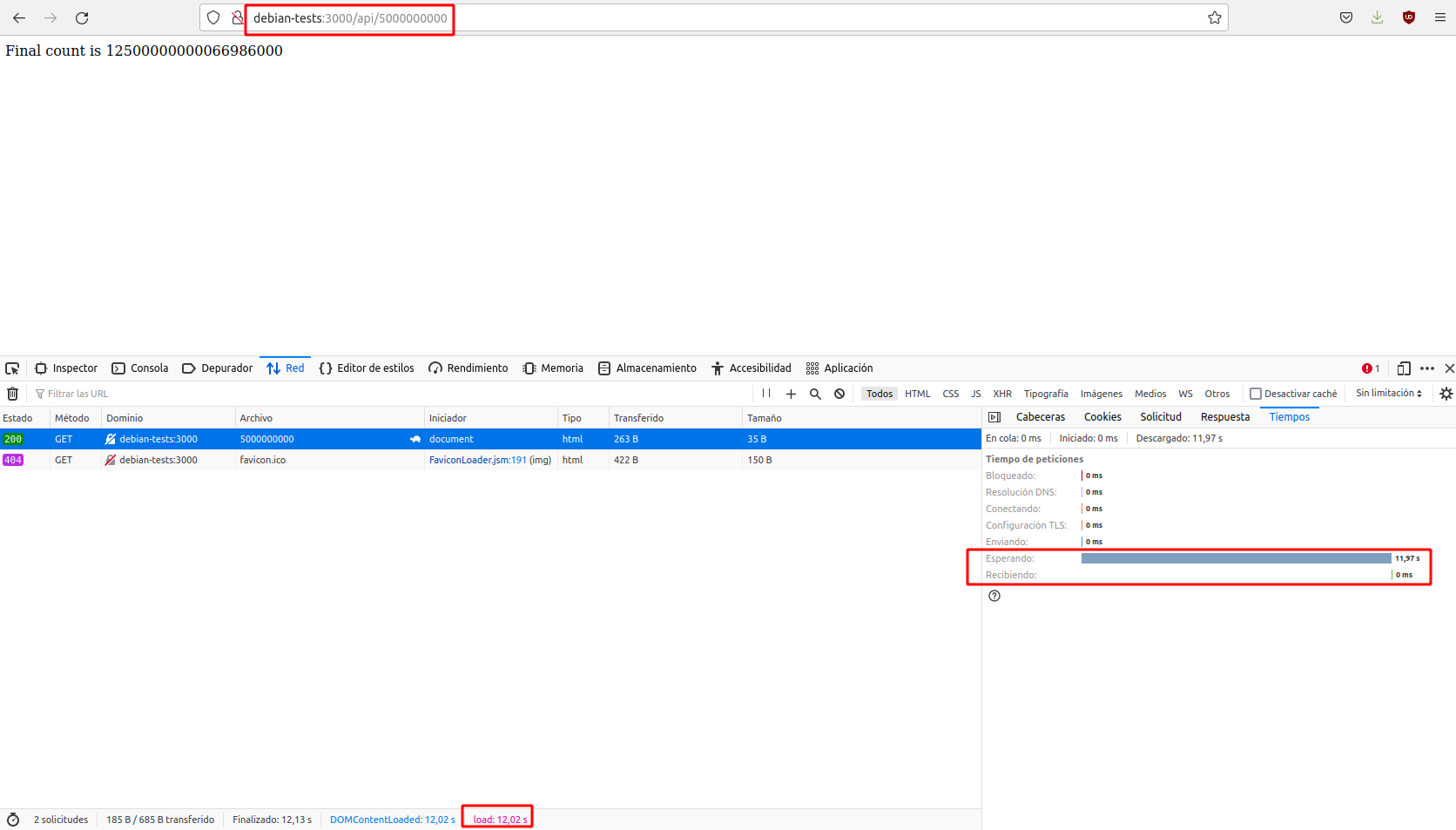
Ahora ya sabemos lo que le cuesta a nuestro servidor ejecutar el programa para un valor de 50 y uno de 5000000000 cuando solo está ejecutando un proceso. Veamos qué pasa si tiene que ejecutar 2 a la vez. Prepara 2 pestañas en tu navegador, con las herramientas para desarrolladores activadas y en una de ellas la URL http://IP-maq-virtual:3000/api/5000000000 y en la otra http://IP-maq-virtual:3000/api/50.
Ya está el entorno de pruebas listo. Ahora ejecuta el programa con el 5000000000. Mientras esta solicitud que tarda unos segundos se está procesando, acceded a la otra pestaña del navegador con http://IP-maq-virtual:3000/api/50 y ejecutalo.
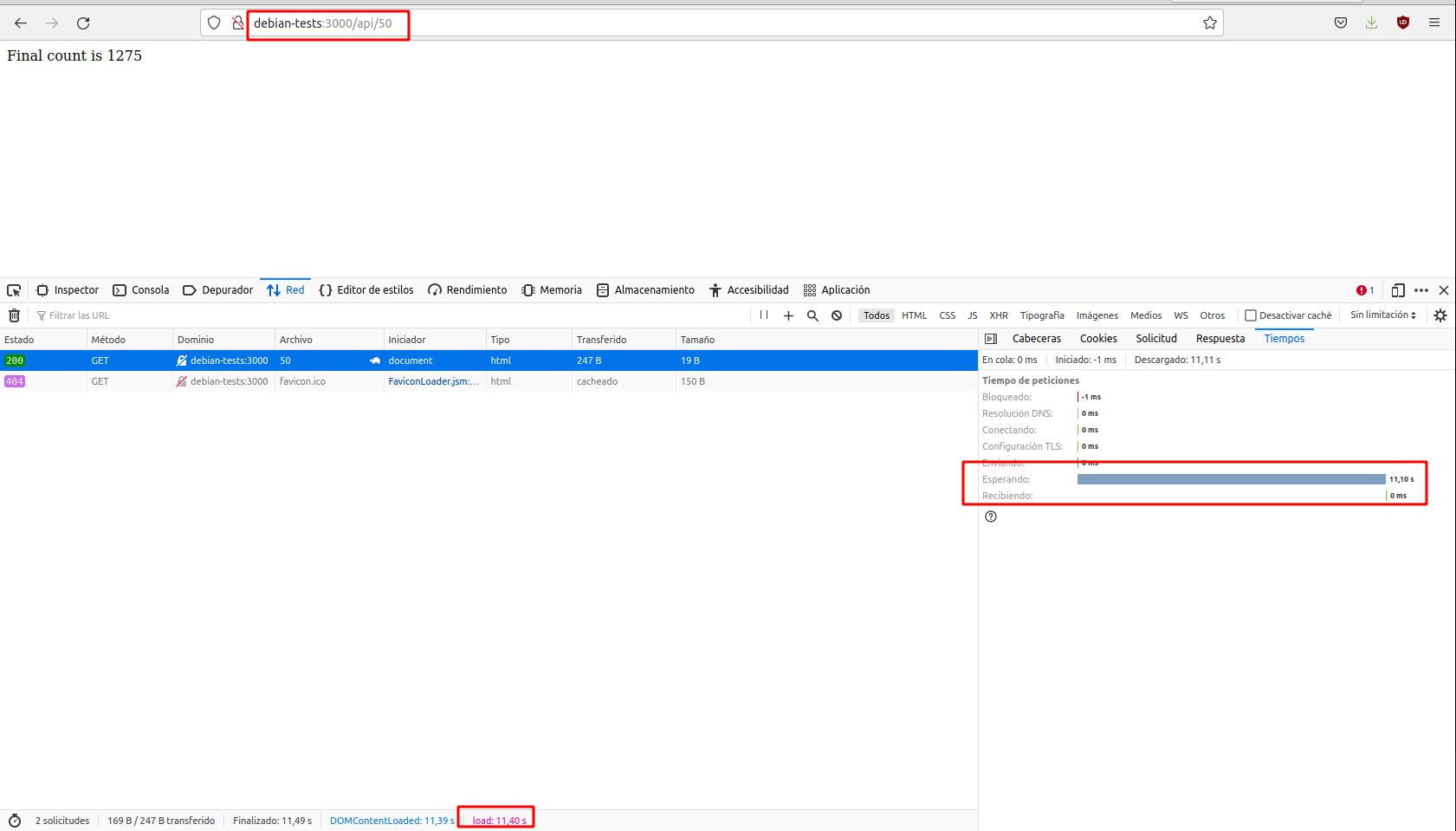
Utilizando las devoloper tools, podemos ver el tiempo que tardan en procesarse las solicitudes:
- La primera solicitud, al tener un valor de
ngrande, nos lleva unos cuantos segundos completarla. Más o menos como antes - La segunda solicitud, pese a tener un valor de
50que ya habíamos comprobado que ofrecía una respuesta de milisegundos, también se demora unos segundos.
¿Por qué ocurre esto? Porque el único subproceso estará ocupado procesando la otra operación de ejecución prolongada. El único núcleo de la CPU tiene que completar la primera solicitud antes de que pueda encargarse de la otra. Así que la segunda tarda lo que le queda de proceso a la primera, que está esperando más su tiempo de ejecución.
¡Ahora con más clúster!
Ahora usaremos el módulo de clúster en la aplicación para generar algunos procesos secundarios y ver cómo eso mejora las cosas.
A continuación se muestra la aplicación modificada:
const express = require("express");
const port = 3000;
const cluster = require("cluster");
const totalCPUs = require("os").cpus().length;
if (cluster.isMaster) {
console.log(`Number of CPUs is ${totalCPUs}`);
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < totalCPUs; i++) {
cluster.fork();
}
cluster.on("exit", (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
console.log("Let's fork another worker!");
cluster.fork();
});
} else {
const app = express();
console.log(`Worker ${process.pid} started`);
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.get("/api/:n", function (req, res) {
let n = parseInt(req.params.n);
let count = 0;
if (n > 5000000000) n = 5000000000;
for (let i = 0; i <= n; i++) {
count += i;
}
res.send(`Final count is ${count}`);
});
app.listen(port, () => {
console.log(`App listening on port ${port}`);
});
}
child_process.fork(). El método devuelve un objeto ChildProcess que tiene un canal de comunicación incorporado que permite que los mensajes se transmitan entre el hijo y su padre.
Creamos tantos procesos secundarios como núcleos de CPU hay en la máquina en la que se ejecuta la aplicación. Se recomienda no crear más workers que núcleos lógicos en la computadora, ya que esto puede causar una sobrecarga en términos de costos de programación. Esto sucede porque el sistema tendrá que programar todos los procesos creados para que se vayan ejecutando por turnos en los núcleos.
Los workers son creados y administrados por el proceso maestro. Cuando la aplicación se ejecuta por primera vez, verificamos si es un proceso maestro con isMaster. Esto está determinado por la variable process.env.NODE_UNIQUE_ID. Si process.env.NODE_UNIQUE_ID tiene valor undefined, entonces isMaster será true.
Si el proceso es un maestro, llamamos a cluster.fork() para generar varios procesos. Registramos los ID de proceso maestro y worker. Cuando un proceso secundario muere, generamos uno nuevo para seguir utilizando los núcleos de CPU disponibles.
Ahora repetiremos el mismo experimento de antes, primero realizamos una solicitud al servidor con un valor alto n:
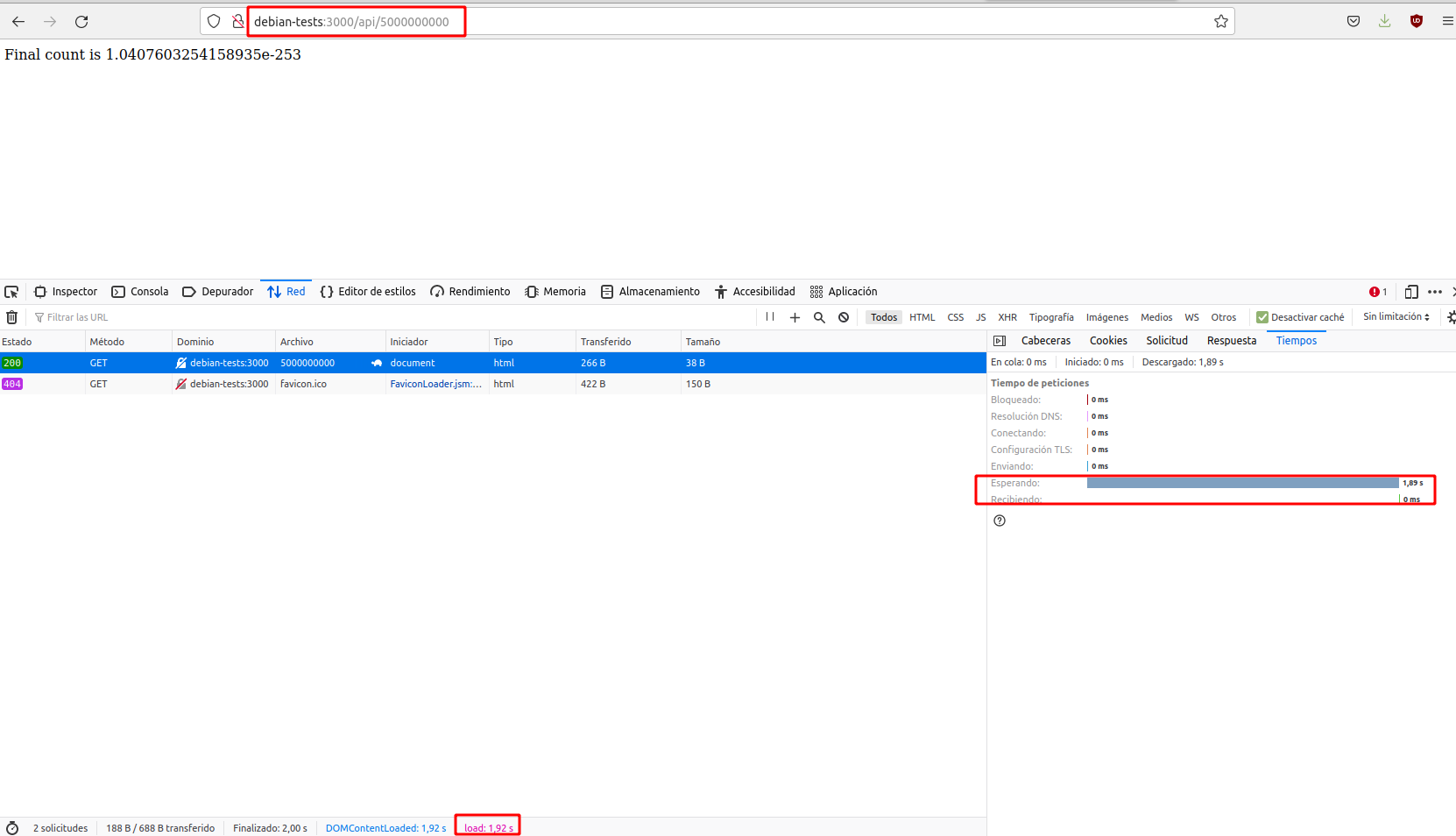
Y ejecutamos rápidamente otra solicitud en otra pestaña del navegador, midiendo los tiempos de procesamiento de ambas:
Comprobaremos que éstos se asemejan mucho más a los que obtuvimos ejecutando la aplicación de forma independiente.
Note
Con varios workers disponibles para aceptar solicitudes, se mejoran tanto la disponibilidad del servidor como el rendimiento.
Ejecutar una solicitud en una pestaña del navegador y ejecutar rápidamente otra en una segunda pestaña sirve para mostrarnos la mejora que ofrece la agrupación en clústeres para nuestro ejemplo de una forma más o menos rápida, pero es un método un tanto "chapucero" y no es una forma adecuada o confiable de determinar las mejoras de rendimiento.
En el siguiente apartado echaremos un vistazo a algunos puntos de referencia que demostrarán mejor cuánto ha mejorado la agrupación en clústeres nuestra aplicación.
Métricas de rendimiento
Realizaremos una prueba de carga en nuestras dos aplicaciones para ver cómo cada una maneja una gran cantidad de conexiones entrantes. Usaremos el paquete loadtest para esto.
El paquete loadtest nos permite simular una gran cantidad de conexiones simultáneas a nuestra API para que podamos medir su rendimiento.
Para usar loadtest, primero debemos instalarlo globalmente. Tras conectaros por SSH al servidor Debian:
Luego ejecutamos la aplicación que queremos probar (node nombre_aplicacion.js). Comenzaremos probando la versión que no utiliza la agrupación en clústeres.
Mientras ejecutamos la aplicación, en otro terminal realizamos la siguiente prueba de carga:
El comando anterior enviará 1000 solicitudes a la URL dada, de las cuales 100 son concurrentes. El siguiente es el resultado de ejecutar el comando anterior:
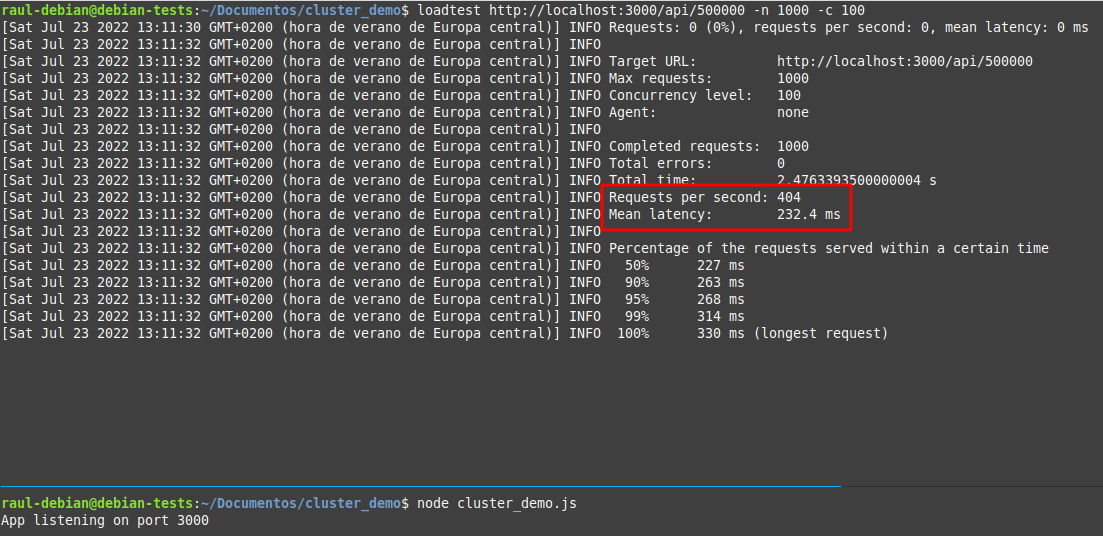
Vemos que con la misma solicitud (con n= 500000) el servidor ha podido manejar 404 solicitudes por segundo con una latencia media de 232.4 milisegundos (el tiempo promedio que tarda en completar una sola solicitud). Anota los datos que obtienes en tu caso.
Intentémoslo de nuevo, pero esta vez con un n mayor n=5000000 (y sin clústeres):
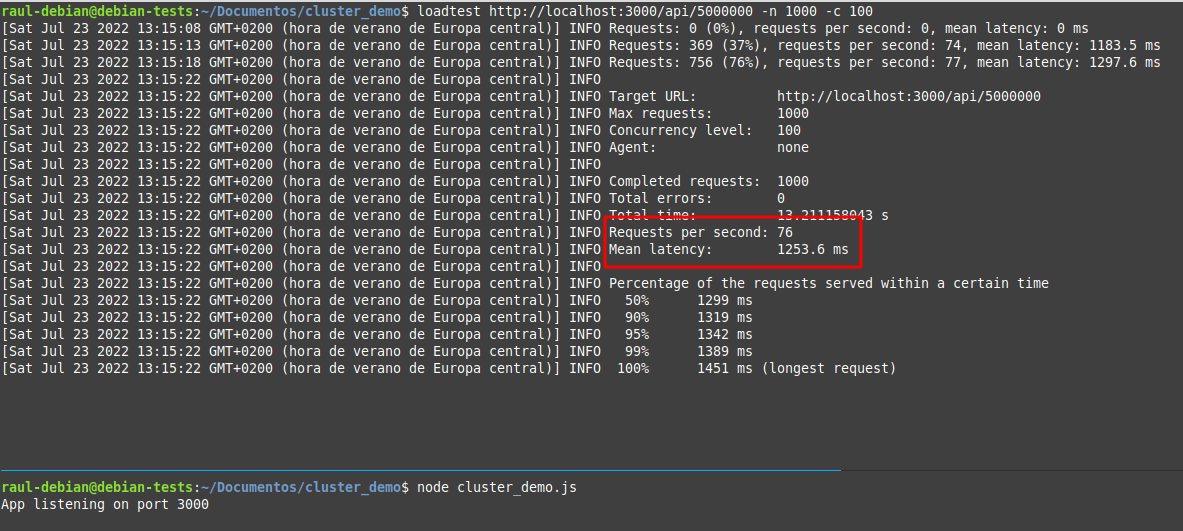
Vemos que las métricas arrojan resultados peores. Anota los datos que obtienes en tu caso.
Ahora detenemos nuestra aplicación sin clústers y ejecutamos la que sí los tiene (node nombre_aplicacion_cluster.js). Ejecutaremos exactamente las mismas pruebas con el objetivo de realizar una comparación:
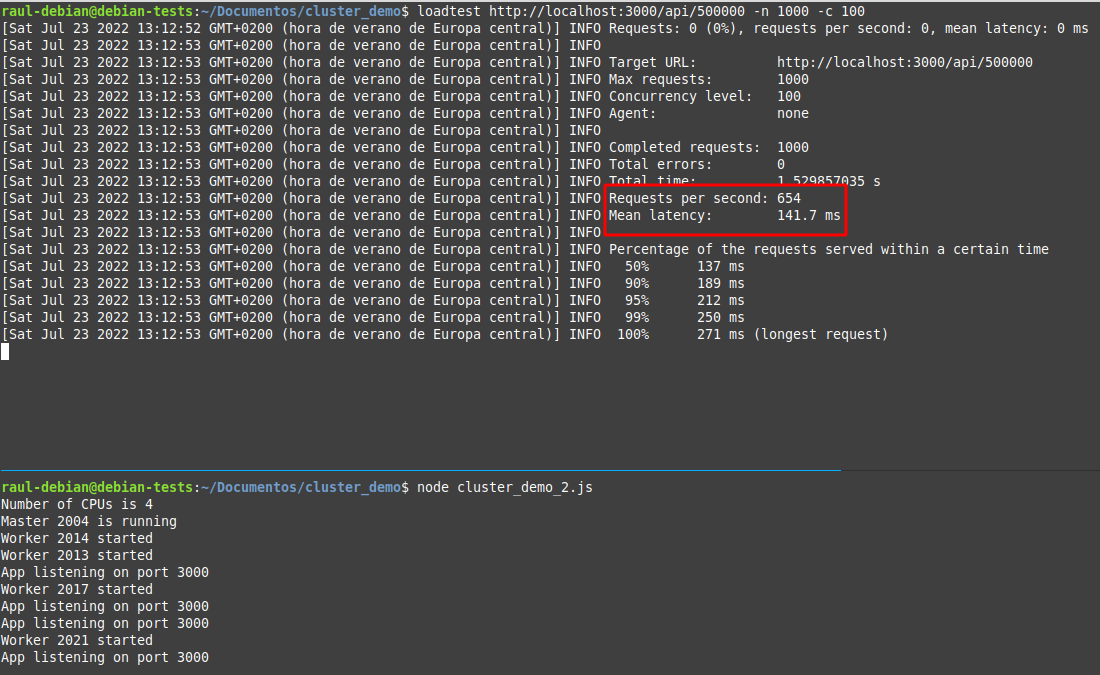
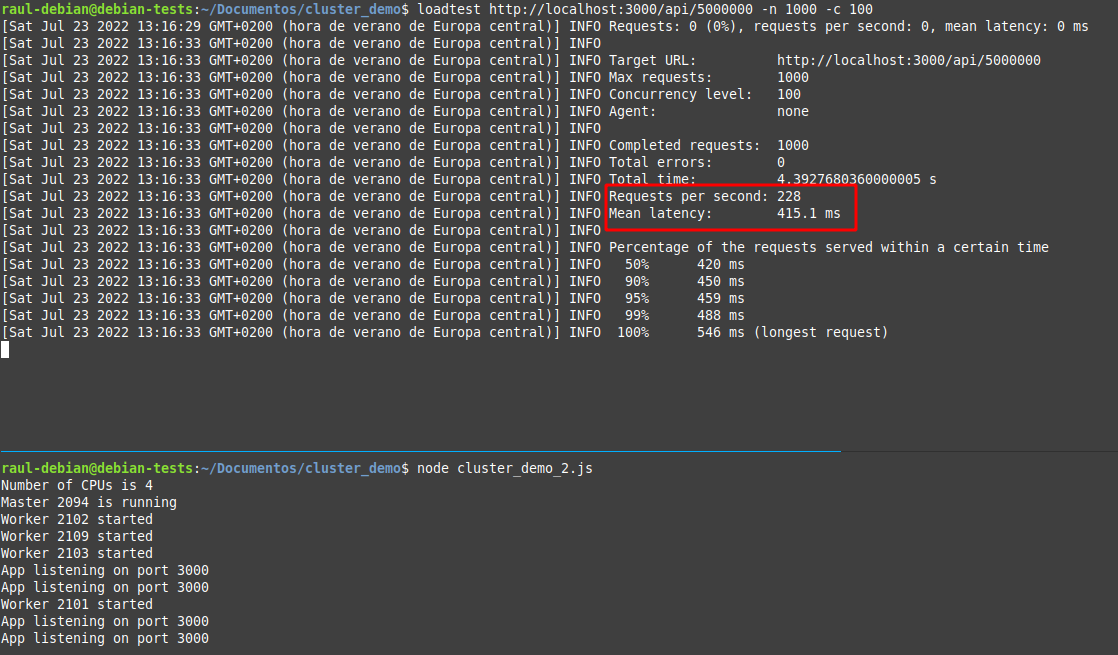
Anota los datos que obtienes en tu caso y compáralos con los obtenidos en la aplicación sin clusters. Es obvio que los clústers permiten manejar una mayor cantidad de peticiones por segundo con una menor latencia.
Uso de PM2 para administrar un clúster de Node.js
En nuestra aplicación, hemos usado el módulo cluster de Node.js para crear y administrar manualmente los procesos.
Primero hemos determinado la cantidad de workers (usando la cantidad de núcleos de CPU como referencia), luego los hemos generado y, finalmente, escuchamos si hay workers muertos para poder generar nuevos.
En nuestra aplicación de ejemplo muy sencilla, tuvimos que escribir una cantidad considerable de código solo para administrar la agrupación en clústeres. En una aplicación de producción es bastante probable que se deba escribir aún más código.
Existe una herramienta que nos puede ayudar a administrar todo esto un poco mejor: el administrador de procesos PM2. PM2 es un administrador de procesos de producción para aplicaciones Node.js con un balanceador de carga incorporado.
Cuando está configurado correctamente, PM2 ejecuta automáticamente la aplicación en modo de clúster, generando workers y se encarga de generar nuevos workers cuando uno de ellos muera.
PM2 facilita la parada, eliminación e inicio de procesos, además de disponer de algunas herramientas de monitorización que pueden ayudarnos a monitorizar y ajustar el rendimiento de su aplicación.
Para usar PM2, primero instalamos globalmente en nuestra Debian:
Vamos a utilizarlo con nuestra primera aplicación, la que no estab "clusterizada" en el código. Para ello ejecutaremos el siguiente comando:
Donde:
-
-ile indicará a PM2que inicie la aplicación encluster_mode(a diferencia defork_mode).Si
se establece a 0, PM2generará automáticamente tantos workers como núcleos de CPU haya.
Y así, nuestra aplicación se ejecuta en modo de clúster, sin necesidad de cambios de código.
Comprueba que hay 2 procesos de tu aplicación funcionando:
Task
Ejecuta las mismas pruebas que antes pero utilizando PM2 y comprueba si se obtienen los mismos resultados.
Por detrás, PM2 también utiliza el módulo cluster de Node.js, así como otras herramientas que facilitan la gestión de procesos.
En el Terminal, obtendremos una tabla que muestra algunos detalles de los procesos generados:
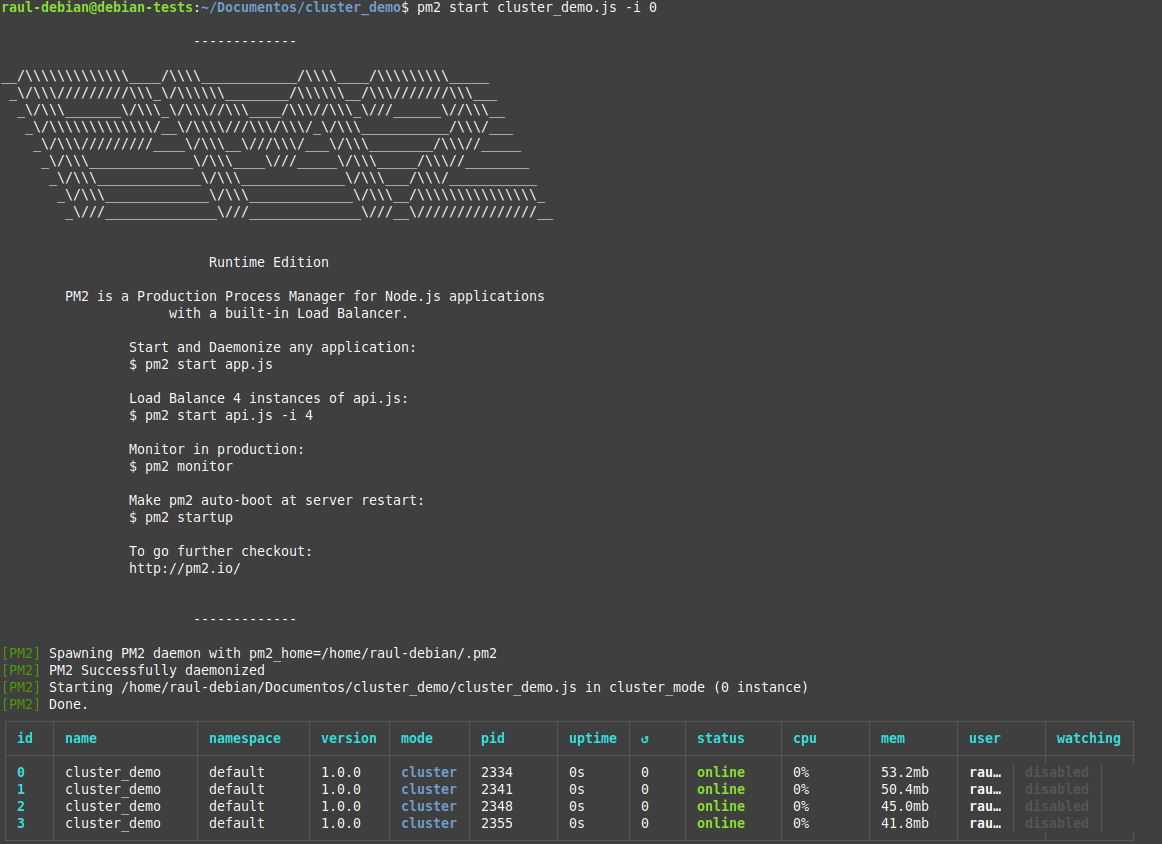
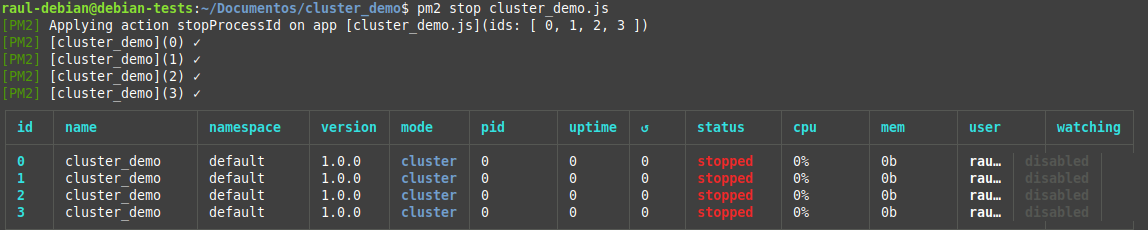
Podemos detener la aplicación con el siguiente comando:
La aplicación se desconectará y la salida por terminal mostrará todos los procesos con un estado stopped.
En vez de tener pasar siempre las configuraciones cuando ejecuta la aplicación con pm2 start app.js -i 0, podríamos facilitarnos la tarea y guardarlas en un archivo de configuración separado, llamado Ecosystem.
Este archivo también nos permite establecer configuraciones específicas para diferentes aplicaciones.
Crearemos el archivo Ecosystem con el siguiente comando:

Que generará un archivo llamado ecosystem.config.js. Para el caso concreto de nuestra aplicación, necesitamos modificarlo como se muestra a continuación:
module.exports = {
apps: [
{
name: "nombre_aplicacion",
script: "nombre_aplicacion_sin_cluster.js",
instances: 0,
exec_mode: "cluster",
},
],
};
Al configurar exec_mode con el valor cluster, le indica a PM2 que balancee la carga entre cada instancia. instances está configurado a 0 como antes, lo que generará tantos workers como núcleos de CPU.
La opción -i o instances se puede establecer con los siguientes valores:
-
0omax(en desuso) para "repartir" la aplicación entre todas las CPU -
-1para "repartir" la aplicación en todas las CPU - 1 -
númeropara difundir la aplicación a través de un número concreto de CPU
Ahora podemos ejecutar la aplicación con:
La aplicación se ejecutará en modo clúster, exactamente como antes.
Podremos iniciar, reiniciar, recargar, detener y eliminar una aplicación con los siguientes comandos, respectivamente:
$ pm2 start nombre_aplicacion
$ pm2 restart nombre_aplicacion
$ pm2 reload nombre_aplicacion
$ pm2 stop nombre_aplicacion
$ pm2 delete nombre_aplicacion
# Cuando usemos el archivo Ecosystem:
$ pm2 [start|restart|reload|stop|delete] ecosystem.config.js
El comando restart elimina y reinicia inmediatamente los procesos, mientras que el comando reload logra un tiempo de inactividad de 0 segundos donde los workers se reinician uno por uno, esperando que aparezca un nuevo worker antes de matar al anterior.
También puede verificar el estado, los registros y las métricas de las aplicaciones en ejecución.
Task
Investiga los siguientes comandos y explica que salida por terminal nos ofrecen y para qué se utilizan:
Cuestiones
Fijáos en las siguientes imágenes:
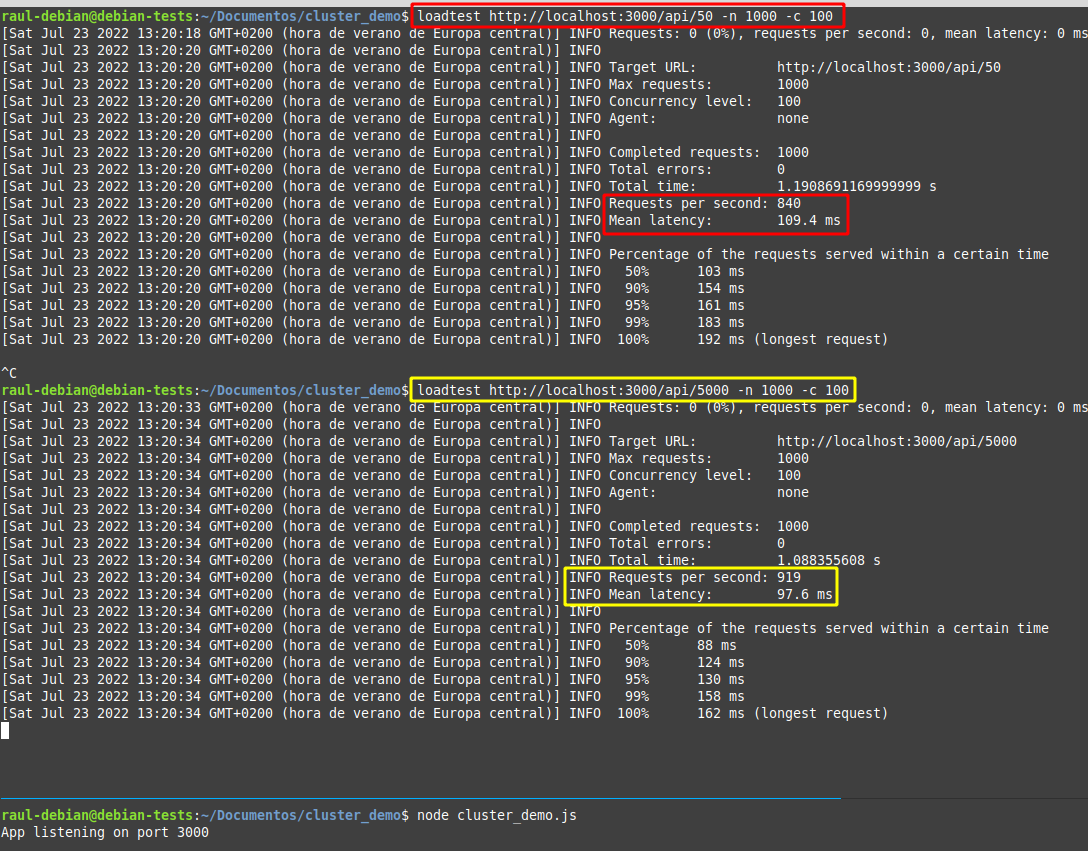
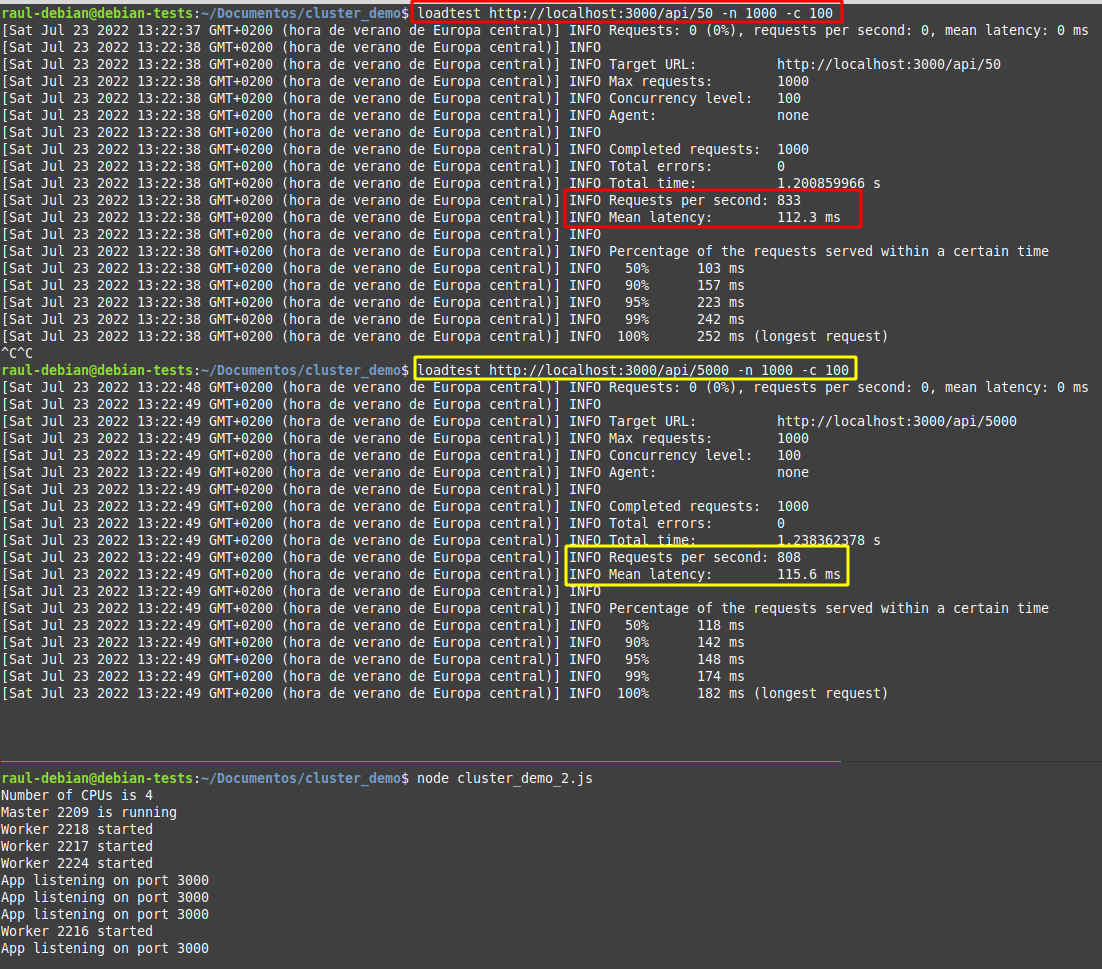
La primera imagen ilustra los resultados de unas pruebas de carga sobre la aplicación sin clúster y la segunda sobre la aplicación clusterizada.
¿Sabrías decir por qué en algunos casos concretos, como este, la aplicación sin clusterizar tiene mejores resultados?